
An AI marking case study: from four hours to twenty minutes
AI assessment can remove workload without removing the teacher

At No More Marking, we have been using Comparative Judgement to assess writing for nearly ten years. Until last year, our main recommendation was for schools to take part in one of our national assessment projects, where we set the task, thousands of students from hundreds of schools take part, and schools get nationally standardised data.
We have now added in AI to all of our assessments. AI has sped up those national assessments, and it has also made it much easier and quicker for individual teachers to use our platform to assess just one class of students.
In this article, I have a fantastic case study from King Edward VI School, Stratford-upon-Avon. Their English teacher, Amaryllis Barton, used our system to provide 26 Year 9 students with accurate data and personalised human feedback in under 20 minutes.
Amaryllis set up this task herself using the advice on our help site but with no extra support. It worked so well that we think it deserves a wider audience.
The task
Amaryllis was teaching a non-fiction writing unit that culminated in students writing a magazine article about how animals help humans and why they are often described as “man’s best friend”. The final assessment came at the end of a sequence of teaching. Students planned, drafted, received feedback and revised before completing the final piece of writing.
Human and AI judging
Amaryllis followed our recommendations about how many judgements to do and how much AI to use. We recommend doing 10 judgements per script, and getting the human teacher(s) to do 10% of them. In this case, that meant the human teachers doing 26 judgements. Amaryllis chose to do all 26 judgements herself.
Every judgement involves 2 scripts. So if you do 26 judgements, you will see 52 scripts. This means every script was seen twice by Amaryllis. This is a very important point! People quite rightly worry that AI assessment means teachers stop engaging with student writing, and that this could have a knock-on effect on student engagement. Why bother working hard on a piece of writing when your teachers can’t be bothered to read it? But in the system we have designed, every script is seen twice by a human, which is double what happens with traditional non-AI rubric based assessment.
In the past, we have recommended getting lots of teachers involved to do the judging. Adding in the AI makes it possible for just one teacher to complete all the required human judging.
After combining all of Amaryllis’s judgements with the AI judgements, the overall reliability of the judging was 0.88, which is pretty good (1 is perfect). Amaryllis also had a 62% agreement with the AI. This is a bit lower than we are used to, but on review most of the disagreements were quite small, as the class had a narrow ability range, and Amaryllis was happy with the overall scores.
Human and AI feedback
The AI automatically generated a page of student friendly feedback for each student, using the criteria provided by Amaryllis.
However, as well as this feedback, she also used the AI-assisted audio feedback function on our website. This is one of my favourite features in the platform and one I would love to see used more widely.
While judging, teachers can click a microphone button and speak their feedback. The AI transcribes what they say, polishes it and turns it into a written comment in student friendly language.
Again, this is a safeguard against teacher and student disengagement. The audio feedback is not AI feedback, it is human feedback and it shows the student that the teacher has read their work. But because speaking is much faster than typing, it is much more efficient.
Amaryllis therefore provided students with two forms of feedback.
Audio comments generated from her own spoken observations.
Direct AI-generated feedback.
These were combined together into a booklet for each student which also included their script. Here is an extract from one student’s booklet.




How long did it take?
Amaryllis did 26 judgements, which involved her looking at each script twice. She left one audio comment on each script. On average, each decision took her 41.5 seconds, which includes leaving the audio comments. So she got all of her judging done in under 20 minutes. Below you can see all the key data from the judging panel.
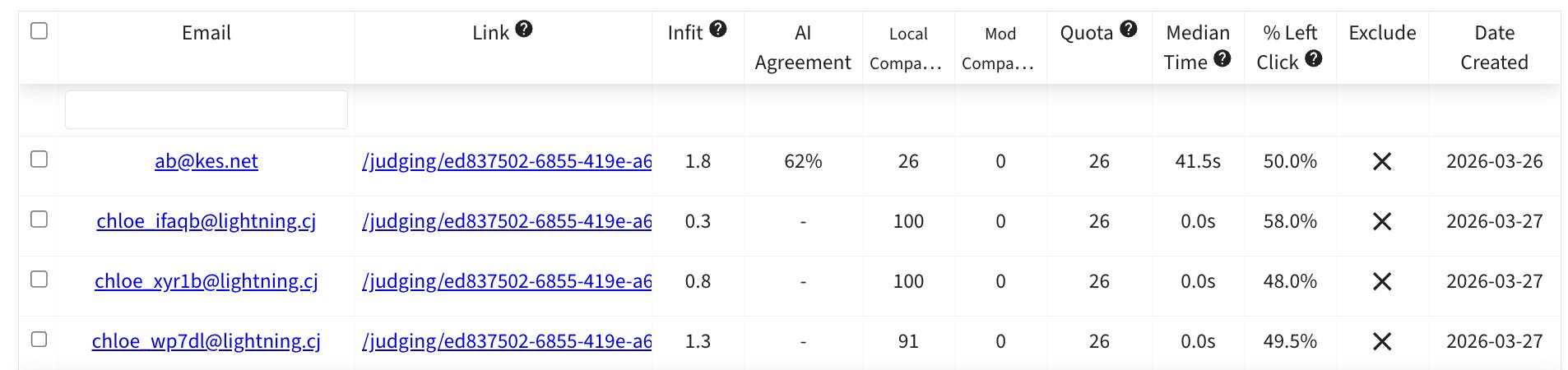
That is incredibly rapid. I used to be a secondary English teacher, and using traditional marking, I would estimate that it would take me at least four hours, maybe more, to produce this level of quality personalised feedback and reliable scores.
Is this a realistic use case? Could other teachers copy this? Amaryllis did say that the process was quicker because she knew the students well and had been working with them on their writing throughout the whole unit, reading drafts and sharing student examples throughout the process. It would take longer if it was a cold exam task and you had no idea what the students were writing about. Still, even if it took double the time it is still far more efficient than traditional marking.
What did the students make of it all?
Amaryllis told the students at the start of the unit that they would be getting a mix of AI and human feedback and that the AI would help her mark it. They liked the idea and enjoyed getting the mix of feedback!
One slight problem was that one of our pre-set AI feedback headings was about capital letters. Most of the students used capitals correctly. The AI noted this, but then often made an ambiguous comment about “making sure you use them correctly in the future.”

A lot of the students didn’t like this, and given most of them didn’t have an issue with capitals, maybe in the future they don’t need this as a feedback category. For the next task, Amaryllis will be able to set what the feedback headings are
As part of the feedback lesson, the class reflected on what they had learnt about teacher feedback and AI. The class said that knowing a human has read their work was much more important to them than they had originally thought. They were only able to accept and act upon the AI comments if they knew their teacher agreed with them! They also realised that they liked the AI feedback best if it was helping them to improve, rather than simply to give them a grade.
What next?
The school’s English department is planning another AI assessment with all its Year 8 English classes, this time on dystopian fiction. The major area for improvement will be refining the direct AI feedback. We also have a new system in place that automatically creates personalised multiple-choice questions, so we’re going to see how that works too.
If you would like to try out something similar, you can do so for free. You can book a call with me here where I will set you up with 30 free credits – enough to assess 30 essays.
I am not clear on the methodology of this study. How many students in total were being marked? I particularly found this confusing “Every judgement involves 2 scripts. So if you do 26 judgements, you will see 52 scripts. This means every script was seen twice by Amaryllis” What is a judgment? is that feedback with a mark? The way that this is written it sounds like that two scripts, produced by a two different students, are getting one set of feedback? If she is looking at every script twice how is this 10% of the total. I think this bit could have been clearer
Did the AI not pick up on the fact that the student seems to be describing the first world war in 1940?