
Can Comparative Judgement predict the future?
Predicting this summer's Year 6 writing results

We’ve been running Comparative Judgement writing assessments in England & Wales primary schools since 2017-18. We kept going during the pandemic - unlike the national statutory writing assessments - so we have a set of data that allows us to track writing attainment over time and see the impact of Covid.
We can also compare the results of our assessments with those from the government assessments. This is important, because a frequent - and understandable - question that we get from all schools and indeed all users of Comparative Judgement is: does this approach give you the same results that you’d get from more traditional assessments?
Comparative Judgement is a very different way of assessing that feels very subjective, but delivers highly reliable results. It’s the opposite of traditional marking with a rubric, which feels very objective, but often delivers quite unreliable results.
We - and others - have carried out a few studies (eg see here and here) that basically conclude yes, students will get the same results- they’ll just be more reliable and it won’t take you as long!
Last week, thanks to a question from Michael Tidd, one of our primary headteacher subscribers, we realised that we could analyse our existing data in a way that would shed some more light on this question.
The three year national assessment gap brought about by the pandemic has thrown up an interesting natural experiment.
Back in summer 2019, the last summer of assessments before the pandemic, 20% of Year 6 pupils got GDS in the government writing assessments. This corresponded to a mark of 578 on our Comparative Judgement assessment held in March 2019.
So let’s assume that 578 is the pre-pandemic GDS standard.
If we applied 578 to our March 2022 assessment, what percentage would have reached it? 15%.
In summer 2022, what percentage reached GDS on the government assessment? 13%.
There’s a similar correspondence at the EXS threshold too. Our pre-pandemic EXS threshold was set at 526, because that was the score achieved by 79% of students in the national assessment in 2019.
If we applied 526 to our March 2022 assessment, what percentage would have reached it? 70%.
In summer 2022, what percentage reached GDS on the government assessment? 69%.
This close correspondence is pretty remarkable. It suggests that our March 2022 assessment was able to predict the summer national assessment to a high degree of accuracy. It also suggests that despite the three year gap in national assessments, teachers nationally were able to apply the pre-pandemic standard to students in summer 2022 in the government assessment.
This is pretty remarkable - but is it just a fluke? Well, we will be able to repeat the process this summer too. We’ve recently completed our March 2023 Year 6 assessment. If we again define GDS at 578 and EXS at 526, then we would expect 22% of students to get GDS and 65% EXS.
You might notice something odd about that - we’re predicting that the percentage getting the top grade will go UP quite a lot - and the percentage getting the middle grade will go DOWN. This feels a bit counter-intuitive, but it’s because one of the striking findings about nearly all our assessments this year is that the spread of attainment has increased. More pupils are getting the top grade. Fewer are getting the middle grade. More are getting the bottom grade.
Here’s a graph which shows this very clearly. Look at the purple curve, which is this year’s results. It’s much more stretched out than the previous curves. You can clearly see the bulges at either end compared to previous years, showing the greater proportion of students getting the highest and lowest scores.
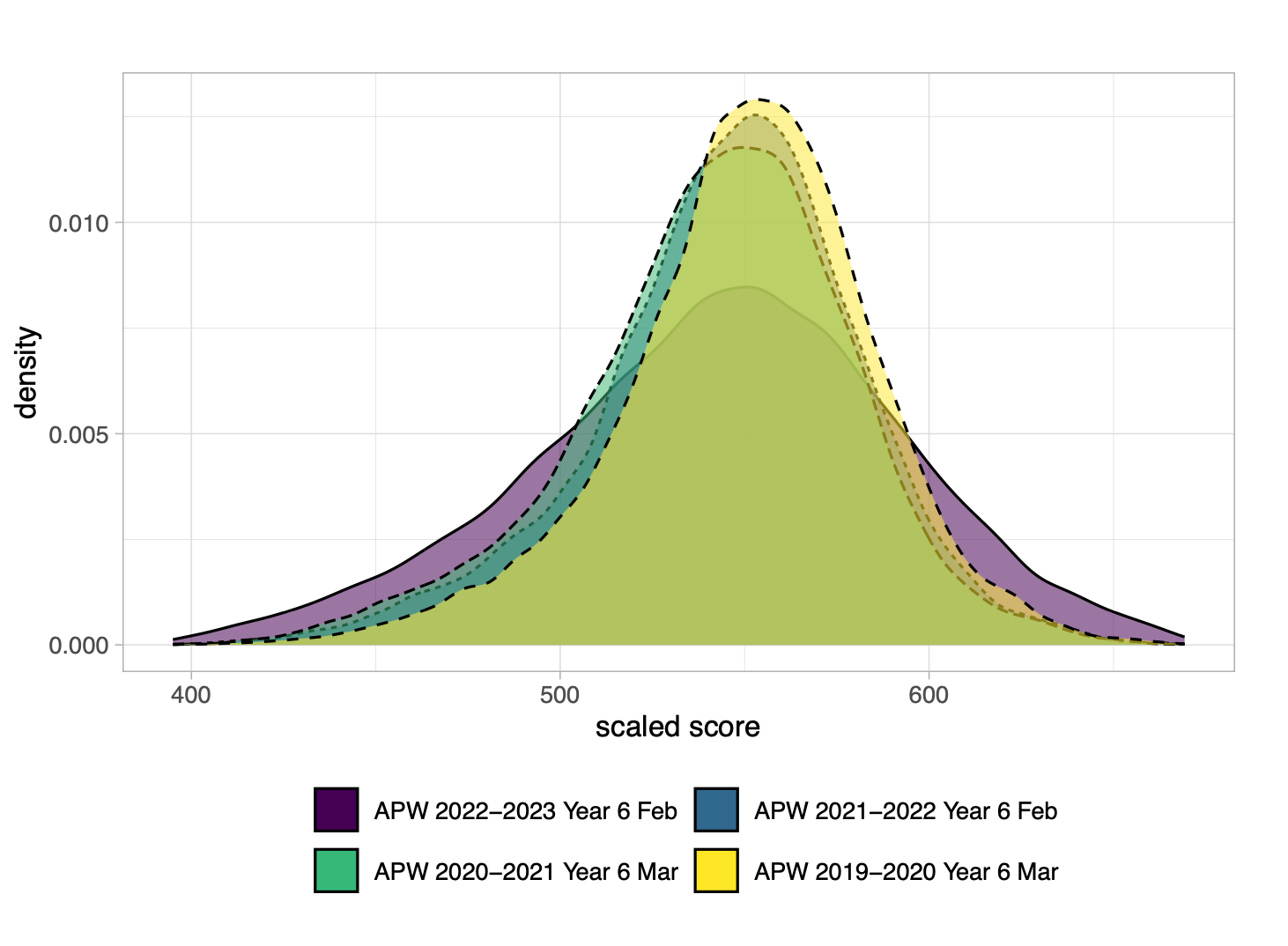
Because of the counter intuitive nature of these results, I’m not that confident that this prediction will be fulfilled. The government assessment is based on teacher judgements, and I can see how teachers might second guess themselves or feel it can’t be right to award such an unusual set of results.
Regardless of whether the 2023 prediction is accurate or not, this analysis has shown that for 2022 at least, Comparative Judgement and the national writing assessment data showed a similar fall in the proportion of students reaching the national standard.
This is a rare recent post where we haven’t mentioned ChatGPT - but we will shoehorn in a mention at the end. We thought it was interesting that in the limited information revealed by OpenAI, they explained how they used human Comparative Judgement to generate the datasets to train their GPT models. It’s essentially an acknowledgement that Comparative Judgement is the gold standard of human judgement. Given the difficulties we’ve had with getting GPT to mark essays reliably, we think it is still the gold standard of judgement full stop!