


Can GPT-3 mark writing? The data is in...
Assessing writing with generative AI


Back in January we asked whether ChatGPT could reliably mark students’ writing.
Since then we have integrated GPT-3 into our Comparative Judgement software and run a trial involving 8 schools.
Here’s how the trial worked
We ran two tasks: one in Year 5 and one in Year 7. Each trial consisted of four schools who submitted writing from 10 students. All the students responded to the same prompt asking them to write about their ideal job. They typed their responses.
The teachers judged all the scripts using Comparative Judgement (CJ). The internal reliability of both the Comparative Judgement tasks was 0.85.
We then asked GPT-3 to mark each script using a level of response mark scheme with 8 level descriptors. We got it to triple mark each script and took the average of the 3 marks. We then compared this average AI score with the human CJ score.
The results
The human Comparative Judgement scores were scaled from 0–100. The AI judges gave each script a mark from 1–8 using a levels of response of mark scheme with 8 level descriptors.
For Year 5, the correlation between the human and AI scores was 0.66. For Year 7, the correlation between the human and AI scores was 0.69. Here is a graph of the results.
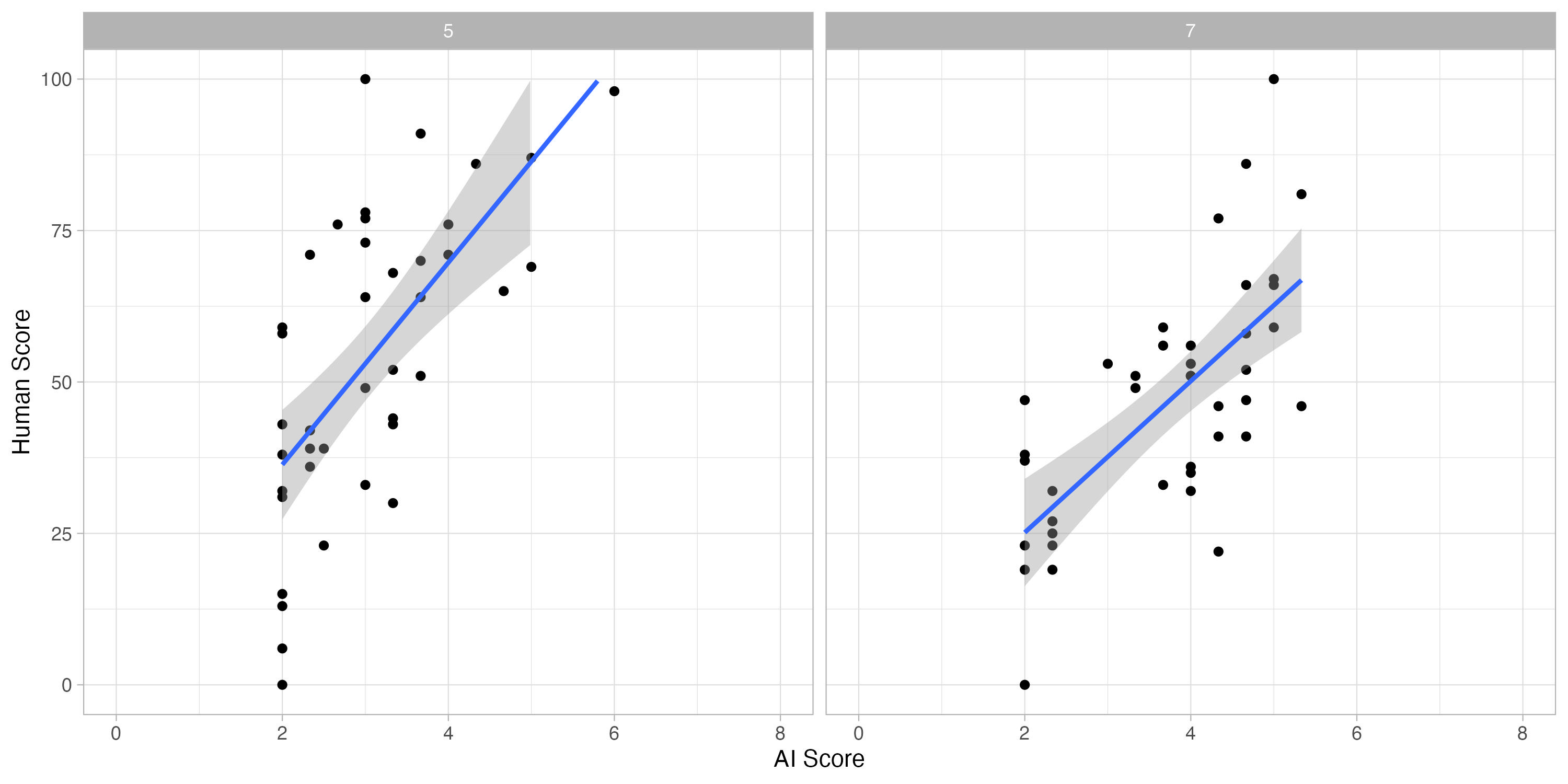
These are not great results.
Clustering
First, the AI clustered its results between grades 2 & 5. Very few scripts were awarded 1, 6, 7 or 8. This clustering inflates the human-AI correlation, making it seem better than it is.
The clustering causes particular problems at grade 2.
In both year 5 and year 7, the AI awarded its lowest grade of 2 to scripts ranging from 0 – 50 on the human scale. It’s failing to differentiate between these scripts.
Individual anomalies
When we looked at the outliers — the scripts where the humans & AI disagreed — we found the AI judgements rather baffling. Here are two good examples. The script on the left was judged to be below average by the human judges, but above average by the AI judges. The script on the right has the opposite profile. We cannot understand how the AI arrived at this conclusion.

We tried a number of different methods and mark schemes to improve the AI judging accuracy. Most of them made it worse! The results here are its best performance.
Based on these results, we do not think that AI assessment using large language models like GPT is good enough to be used in schools or in large-scale assessments at the moment. That’s an empirical judgement based on the data above.
But isn't this still better than human marking?
One common response to poor AI performance is to say ‘well, it might not be perfect, but you have to remember that humans aren’t perfect either’. This is absolutely true. As Paul Meehl pointed out many decades ago, simple algorithms often do beat human judgement because human judgement has many flaws. The fair way of judging AI is not to ask whether it is perfect, but to ask whether it does a better job than humans.
In this case, we don’t think the AI does do a better job than human judgement. We’ll write more about this in future posts, but the results above are no better than traditional human marking, and worse than human Comparative Judgement. Not only that, but the types of mistakes matter, and the types of mistakes the AI makes are likely to have more of a negative impact on teaching and learning than those made by humans.
But won’t the AI get better?
Another common response to poor AI performance is to say ‘well, it’s only going to get better’. A few months ago we would probably have agreed with this, but now we are not so sure. There is no guarantee that any technology will keep improving, and our experience so far has made us more sceptical.
What about feedback?
As well as integrating AI marking into our website, we also integrated an AI feedback tool. We’ll share more results from that shortly.
Technical details: The model we used was davinci, which was the most capable GPT-3 model. Since the trial we have re-run the results against gpt-3.5-turbo and get very similar results. We will re-run with gpt-4 when the API becomes available.
If you’d like an update when we’ve completed that, or if you’d like to stay in touch with our other research and writing, subscribe to our Substack - it’s free!