
More GPT marking data - is it better than humans at predicting future grades?
Our latest GPT study


Back in January we started experimenting to see if ChatGPT could mark writing. We were fairly optimistic, and we put quite a bit of work into integrating the GPT-3 API into our website. All this work means it’s now fairly straightforward for us to assess writing using either human judgement or AI judgement, and to compare the two. Here’s a screenshot of what our new AI website looks like. You can see it makes it easy to add both human and AI judges.
Unfortunately, all our results so far have been underwhelming. We've seen a lot of people on social media sharing examples of ChatGPT giving essays the perfect mark. These generally tend to be one-off examples, and ChatGPT certainly does give some essays the right mark, just as a stopped clock is right twice a day. We are trying to do something more systematic at a larger scale, which is why we did the technical work to plug GPT into our software.
We are not natural AI sceptics - we wouldn't have gone to this bother if we were! We have used different AI models very successfully on another website we run, Automark, and could see that if GPT could mark essays it would be enormously useful. However, we have to be guided by the data we are getting, and so far it isn't great.
In our last post, we reported some data comparing the human and AI marks for 40 Year 5 & Year 7 typed assessments completed in February of this year. In this post, we'll share the data from a larger trial that was structured in a slightly different and more sophisticated way but ended up revealing similar problems with GPT.
The study
From our archive of writing, we transcribed 156 year 5 essays on the subject ‘My ideal job’. All the essays were handwritten and undertaken in exam conditions. The transcription was done by Oxford University Press professional transcribers for the purposes of the AI analysis.
In that same archive, we have stories from the same 156 pupils written in year 6, 18 months later. Our question was the following.
Which is better at predicting the year 6 writing scores of our year 5 pupils, GPT-3 or human judges?
The year 5 & year 6 essays were all judged using Comparative Judgement as part of the Assessing Primary Writing project run by No More Marking. The judges were primary school teachers and the sample of essays used were part of a moderation sample for year 5, so none of the judges would have taught the pupils involved. Some of the essays in year 6 may have been judged by their own teachers, but all essays were presented in an anonymised form.
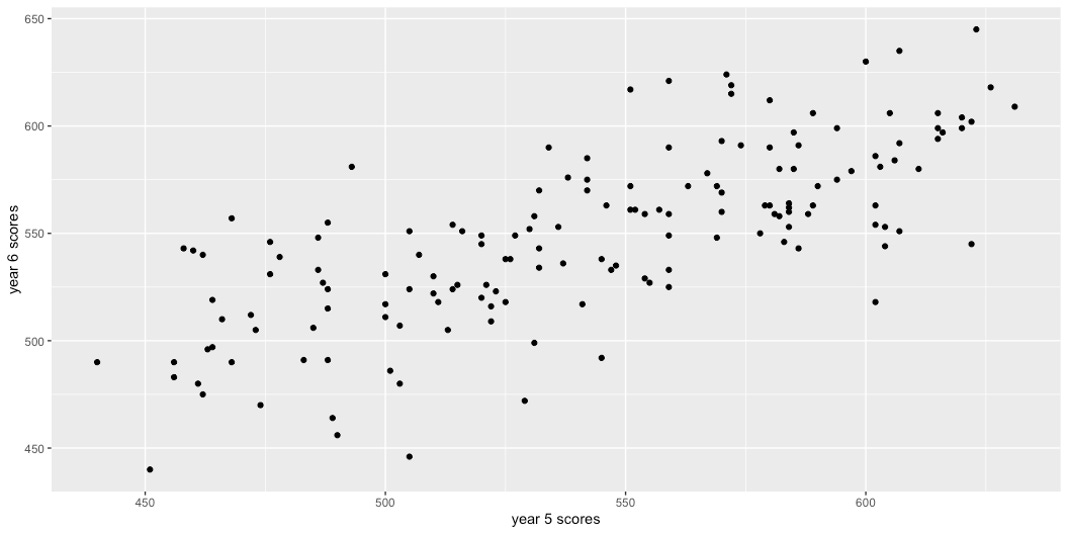
How well does the human judging of year 5 pupils predict the scores of year 6 pupils?
The human judging in year 5 shows a correlation of 0.73 to the year 6 writing scores, which is high given the assessments were taken 18 months apart.
How well does the GPT judging of year 5 pupils predict the scores of year 6 pupils?
The GPT marking in year 5 shows a correlation of 0.54 to the year 6 writing scores, which is substantially lower than the human to human correlation.

Once again we see the same issues with the GPT marking. Essays on the same GPT mark span almost the entire range of the human judging quality scale.
So far, therefore, we have found, in the context of children’s writing:
Poor agreement between human judging and GPT marks
Poor predictive validity for GPT marks
Clustering of marks given by GPT
What’s next
We will replicate this study and all our other ones as soon as we get access to the API of GPT-4. We’ll also share our thoughts about some of the wider educational applications and implications of generative AI.
Who cares what marks it gave. Does it give good feedback for improvement?