
The black box of AI assessment
What is the AI doing when it judges writing?


We have added a lot of new subscribers in the past few weeks - welcome! Our Substack has a mix of big-picture articles about education, assessment and technology - eg, Are we living in a stupidogenic society?; Why education can never be fun - and detailed research from our AI-enhanced Comparative Judgement assessment projects - eg, What is Comparative Judgement and why does it work? and So, can AI assess writing? This is one of the latter, co-written by our Director of Education, Daisy Christodoulou, and our CEO Dr Chris Wheadon. We have future articles coming up on the value of Classics, insights from our new Year 6 redraft project, and whether you can assess creativity or not. Please share with anyone who you think might be interested!
In the world of assessment, we lean on two pillars: reliability and validity.
Reliability is essentially a measure of precision. It asks: If we administer this test multiple times, will we get the same result?
Validity, however, is a much broader, more elusive concept. It asks: Is this result actually meaningful? Does the assessment measure what we intend it to measure?
Imagine a simple spelling test of ten words. It’s likely this kind of test would have high levels of marker reliability, in that different markers would all agree on the score a student should get. However, such a test would not provide you with valid insights about the totality of a student’s writing ability, because it is measuring only one small aspect of writing.
As we hit the one-year mark of introducing AI judges into our assessment processes, it is worth reflecting on the evidence we’ve collected regarding the reliability and the validity of our AI judges.
The reproducible judge
Reliability is relatively easy to quantify: we can give the same set of assessments to different sets of AI judges and measure their agreement. So far, the data is compelling.
Higher agreement: AI judges tend to agree with each other more than human judges do.
Reduced noise: We’ve seen distributions narrow and correlations between assessments increase over time.
Rasch Separation Ratios: Typically, our AI-driven assessments yield higher separation ratios (a statistical measure of internal reliability) than those involving human markers.
Reliability is an important part of the puzzle, and it is a prerequisite for making valid inferences. But, as we have noted before, it isn’t everything. You could have a perfectly reliable system that is telling you something completely meaningless. In an extreme case, an AI could simply be measuring essay length - which is highly reproducible - while a human is looking for a much broader concept of writing quality.
Validity also includes second-order effects. An assessment can work well to begin with, but degrade over time as it influences the way a subject is taught. If an AI only rewards long-windedness, teachers will eventually teach pupils to be long-winded.
But is it meaningful?
So, how does AI hold up on validity? We looked at three key areas:
1. Human-AI Agreement
If humans and AI agree, it suggests they are valuing the same features. In creative writing—an open-ended domain—two humans generally agree on a comparative judgment (which essay is better) about 85% of the time. Our AI judges agree with the human judges about 82–83% of the time. This suggests that, broadly speaking, the AI is valuing the same things in children’s writing that we are.
2. Session-on-Session Correlations
We follow children over time as their writing develops. We expect to see two things: writing should improve with age, and there should be a strong correlation between one session and the next. Our data shows that AI identifies this improvement clearly. In a natural experiment where we split schools between AI and human judges, the correlations were remarkably similar.
3. Theoretical Alignment
We know from years of research that children’s writing improves rapidly at first and then slows down, creating a characteristic growth curve. In a recent session with Australian schools (Years 2–6), our AI judges produced a developmental picture that mapped almost perfectly onto this established curve.
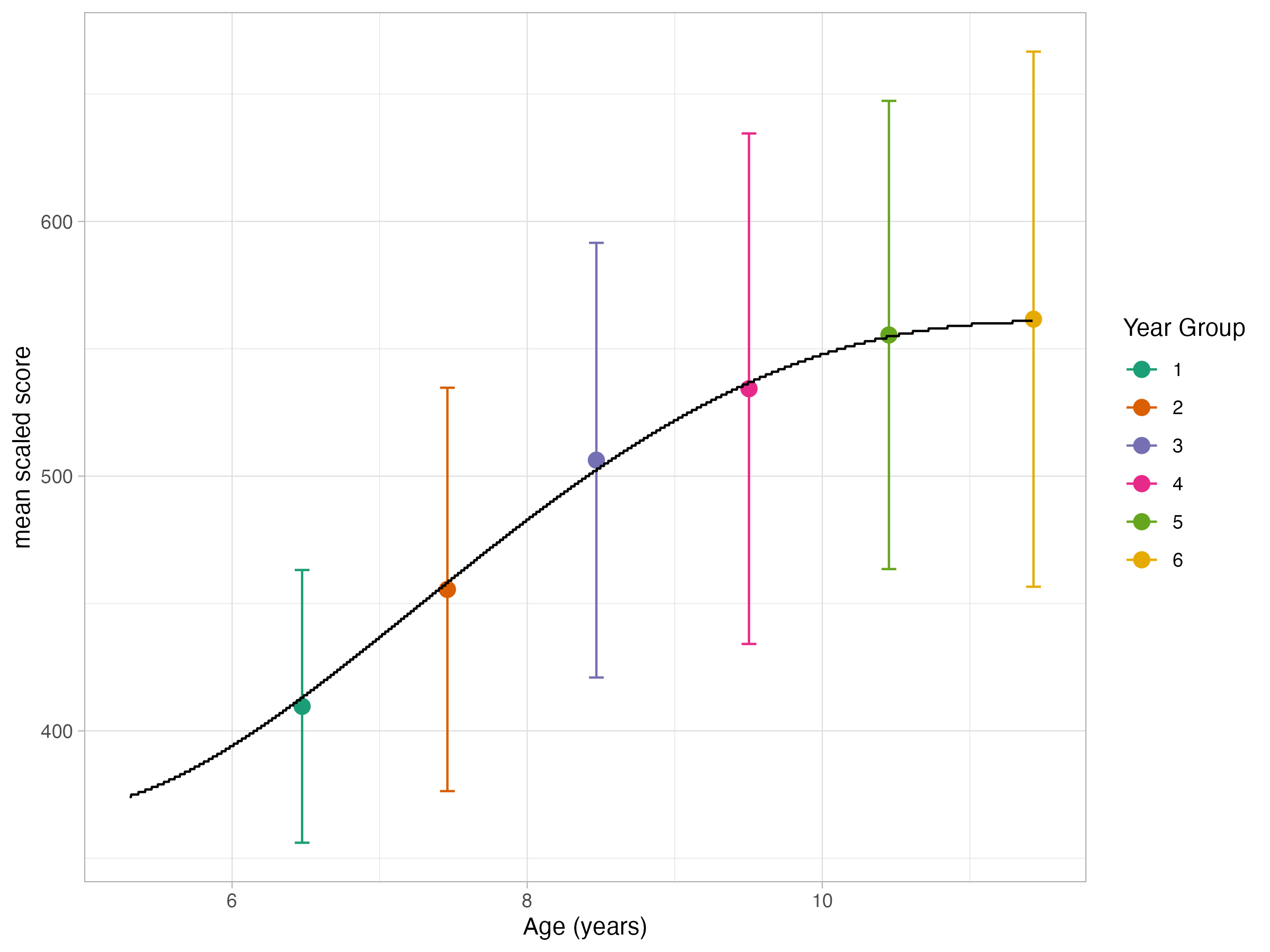
The psychometric perspective from Chris
From the beginning, we’ve faced a theoretical hurdle: How can an AI - sometimes described as a “stochastic parrot” predicting the next word in a sequence - produce meaningful decisions on human creativity?
I’ve moved through stages of scepticism and disbelief. However, after building these models myself, I’ve gained a new perspective. AI models employ vast matrices of probabilities. To a psychometrician, these probabilities are actually quite reassuring; our statistical models are already built on deriving measurements from “stochastic instruments.”
While we may never fully understand the exact “thought process” of an AI as it navigates millions of dimensions of probability, the evidence suggests that it is successfully reproducing human values.
The pedagogical perspective from Daisy
I first wrote extensively about the theory of AI marking in my 2020 book Teachers vs Tech. I discussed the idea that AI markers were unaccountable “black boxes” that can’t explain their decisions, and also considered the possibility that human markers were just as unaccountable and “black box” as the AI!
However, ultimately I concluded with the following: “I still think that we are better off having human judgement involved in marking essays because ultimately, we want our students to learn to write in ways that other humans appreciate.”
I stand by that conclusion, and it’s important to us that our AI-enhanced model includes human judgements. But the reason why I am supportive of using AI judges is that they really do seem to be rewarding the same qualities as our human judges. And, weirdly, there are important ways in which our AI is better at rewarding what humans want than humans are. After every assessment I do a qualitative review of the top essays, the weakest essays and the big human-AI disagreements. Most of the big disagreements do not involve profound philosophical disagreements between human and machine intelligence. They involve humans accidentally pressing the wrong button, or getting misled by bad handwriting.
So far, I simply cannot see any systematic way that you can game the AI judges. In my head, I keep trying to think like a hacker or an adversarial attacker - to find ways that you could get a top mark from the AI judges that you didn’t really deserve. I can’t really find any method that would work!
We will always need to keep monitoring this and ensuring the AI is aligned with humans, and that is why our 90% AI - 10% human model is so important, as it makes sure that every piece of writing is still seen twice by a human, and will immediately alert us to any rogue AI problems.
The patchwork of validity: our next steps
Validity is rarely conclusive. It is a patchwork built over time. We still have work to do, such as:
Addressing outliers: AI still struggles with responses that fall outside its training data.
External variables: We need to see how AI writing scores relate to external tests in reading or mathematics.
Preventing “gaming”: Ensuring the system remains robust against those trying to trick the algorithm. Facial recognition systems are tested using “adversarial attacks” designed to expose their weaknesses. We have a few ideas for something similar!
Addressing “washback”: As teachers and their pupils understand they are being assessed by AI, will teaching and learning change?
We are no longer just theorising about AI in education; we are measuring its impact. And so far, the “strange process” of the AI judge is proving to be a remarkably human-like one.
If you would like to try out our AI judges for yourself - you can!
Our next intro webinar is on Monday! These webinars are very popular - we show you how the system works and at the end we give 30 free credits to all attendees, so you can try it yourself on a class set of essays in any subject.
If you work in a school, you can also book a 30-minute call with me here where I can get you set up on our system with 30 free credits.
While reading your article, the part I thought about most was whether artificial intelligence could be deceived in its evaluation and decision-making in any given situation. I agree with your general idea on this point. However, the question in my mind remains: can artificial intelligence be easily manipulated by humans, another artificial intelligence, or both simultaneously? As you mentioned in the article, studies are being conducted to observe the effects of artificial intelligence after theoretical research. I hope we can get answers to many critical questions as early as possible. Thank you for your intriguing article.
I do the sampling in a similar way but this is the end of process. I feed in the lessons as I teach them. I discuss with the AI what the particular rubric looks like. The students know the generic version. Then I get the AI to rank the essays first before we 'calibrate'. Not my word. That's the sampling. My concern has been with feedback to students. I am not reading 80% of student work, but the 80% are getting much better (quicker, accurate, personalised etc) feedback from the AI than was possible in the past. How should we be managing this? And perhaps more interestingly is the essay still the most reliable and valid test of what we think we are testing? Using AI the students can now generate the dozens of potential exam question answers the exam board may ask. All they need to do then is memorize them.