
Would you ask GPT-4 to mark your essays?
No, and you wouldn't ask an undergraduate who had flunked English to mark them either.

As researchers into the development of language ability we have been following the latest developments in AI carefully. Over the last year we have run a series of experiments to evaluate whether the latest iterations of Large Language Models (LLMs) can mark essays. With the release of the API for GPT-4 last week we can update our experiments with the latest models.
What is GPT-4?
GPT-4 is built using the same architecture as previous GPT models:
Like previous GPT models, the GPT-4 base model was trained to predict the next word in a document, and was trained using publicly available data (such as internet data) as well as data we’ve licensed. The data is a web-scale corpus of data including correct and incorrect solutions to math problems, weak and strong reasoning, self-contradictory and consistent statements, and representing a great variety of ideologies and ideas.
According to OpenAI, the distinction between GPT-3.5 and GPT-4 appears when the complexity of the task reaches a sufficient threshold:
GPT-4 is more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5.
So, can GPT-4 mark essays better than GPT-3.5?
Benchmark assessment
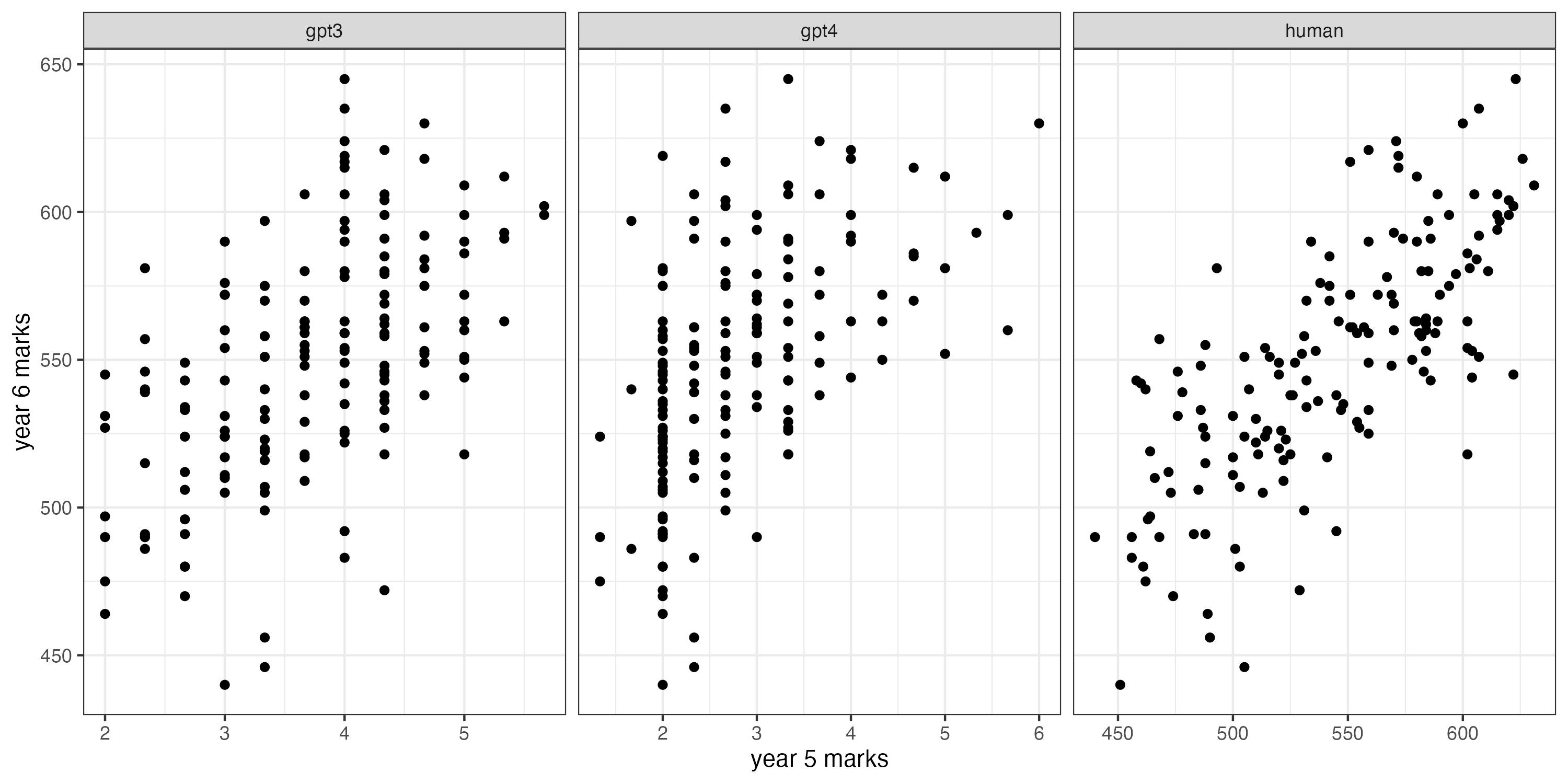
From our archive of writing, we transcribed 156 year 5 essays on the subject ‘My ideal job’. All the essays were handwritten and undertaken in exam conditions. The transcription was done by Oxford University Press professional transcribers for the purposes of the AI analysis.
In that same archive, we have stories from the same 156 pupils written in year 6, 18 months later. Our research question is:
Which is better at predicting the year 6 writing scores of our year 5 pupils, GPT models or human judges?
The year 5 & year 6 essays were all judged using Comparative Judgement as part of the Assessing Primary Writing project run by No More Marking. The judges were primary school teachers and the sample of essays used were part of a moderation sample for year 5, so none of the judges would have taught the pupils involved. Some of the essays in year 6 may have been judged by their own teachers, but all essays were presented in an anonymised form.
Results
GPT-4 performed slightly worse than GPT-3 at predicting the future marks of the pupils. The following table summarises the correlations between the marks produced by GPT models and human judges with the pupils’ future marks.

GPT-4 shows the same issues with lack of discrimination that we had reported with GPT-3.
The limits of LLMs
LLMs can perform some human tasks surprisingly well. A clue to where it will perform is in the analysis of which examinations GPT can pass! GPT models are in the top percentiles of pattern matching tasks such as the GRE style verbal reasoning tasks, but in the lowest percentiles for creative tasks such as AP English Language and Literature. Our advice is don’t let GPT mark your creative subjects, just as you wouldn’t let an undergraduate who had flunked English mark them!
What prompts did you give chatGPT to mark with? Evaluating the prompt you used is fundamental to getting GPT to do anything for you, especially something as complex as marking. I'm little surprised you saw worse performance with GPT-4 being that every piece of research I've seen indicates it performs better than 3.5 in pretty much every task.
AQA are researching whether it is possible to mark short answer STEM questions with AI, but last I heard without much success.