
GPT & Auto Essay Marking
One year on, are we there yet?

Around a year ago Daisy & I believed that GPT was about to have a major impact on essay marking. After a number of trials1, however, we concluded that the marks that emerged from GPT were erratic and the rationale given for the marks little more than pastiche of the mark scheme. Since then, academia has kicked into gear, producing a number of papers that make high claims for GPT models and essay marking. Has someone found the golden model & prompt combination?
So far, the answer appears to be no, with lots of claims that aren’t supported by the data. Generally I would summarise the models as being able to produce weak correlations to human mark scales but unable to discriminate between more than 3 or 4 levels with any effective degree2.
The most recent of the claims is worth investigating in some detail as it does produce some headline catching claims. The authors helpfully summarise their results across a number of models in a single table. Ignoring the usual poor results of the GPT-4 models the GPT-3.5 fine-tuned model jumps out. Once a kappa (a measure of agreement corrected for chance) hits 0.8 then it is in the same ballpark as human markers.
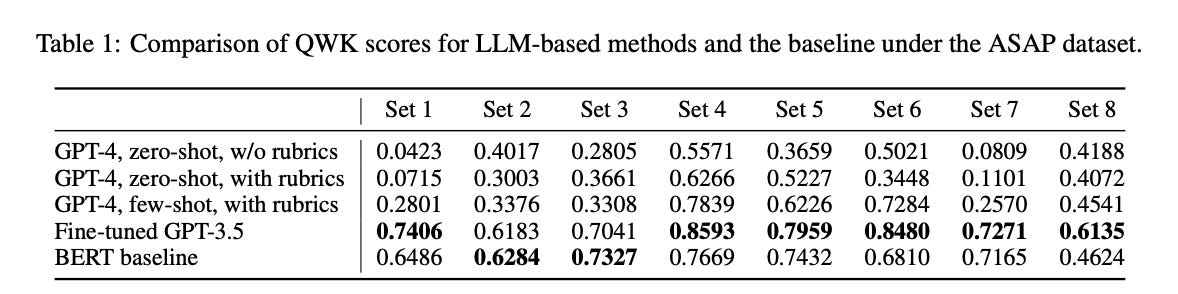
I have learned, however, that the detail of these papers is critical. In this case the Appendices give an admirable level of detail that allow us to attempt to reproduce some of their methodology.
The rubric they use for one dimension jumped out immediately.

Firstly, in reading the rubric, you realise that we are not reading the work of educationalists! There are so many issues with giving a language mark based on the number of errors: the ambition of the writer, the length of the work, the complexity of sentence, the definition of error, the severity of error. I was reminded of why we started using Comparative Judgement in the first place for primary level writing. As soon as you reduce writing to discrete elements of spelling and grammar you punish ambition, flair and creativity and begin to atomise your teaching.
However, leaving all that aside(!), I was intrigued as to whether GPT, which is notoriously bad at maths, could actually mark to this rubric. Using the same prompts and model as the authors I quickly found out that GPT still can’t count. Giving the GPT model a series of GCSE Language essays, the following feedback was typical:
Spelling and grammar errors:
- Sentence: "nobody likes to do it, some people dont do at all." --> "don't" instead of "dont" (1 error)
- Sentence: "it helps with structure and gets you in the correct mind-set" --> "mindset" instead of "mind-set" (1 error)
- Sentence: "it is ther to help you." --> "there" instead of "ther" (1 error)
- Sentence: "According to a study "Homework" has no benefit." --> Incorrect punctuation, should be "According to a study, 'Homework' has no benefit." (1 error)
- Sentence: "But doing homeowrk not in a school setting shows dedication, comitment and good ethics." --> "homework" instead of "homeowrk" (1 error), "commitment" instead of "comitment" (1 error)
- Sentence: "It shows you have a willing to learn and increas your knowledge." --> "a willingness" instead of "a willing" (1 error), "increase" instead of "increas" (1 error)
- Sentence: "Some people say homework only causes anxiety and stress." --> Incorrect capitalization, should be "Some people say homework only causes anxiety and stress." (1 error)
- Sentence: "Teachers have told me if you "set aside time in a nice quiet setting and don't go over your time that you have set aside" it all helps reduce any anxiety or stress the student or person might be experiencing, gently increase the the amount of time you want to spend on homework, it is not a punishment it is to help you and improve on your topic." --> Incorrect punctuation and repeated words, should be "Teachers have told me if you set aside time in a nice quiet setting and don't go over the time you have allocated, it can help reduce anxiety and stress. Gradually increase the amount of time you spend on homework. It is not a punishment, but rather a way to help you improve on your topic." (5 errors)
- Sentence: "If you tuck yourself away in a nice quiet place make sure you have all the tools you need to hand" --> Incorrect punctuation, should be "If you tuck yourself away in a nice quiet place, make sure you have all the tools you need at hand." (1 error)
- Sentence: "reduce any tension that may arise in your family setting" --> Incorrect article, should be "reduce any tension that may arise in a family setting." (1 error)
- Sentence: "the last thing homework should do is cause friction in the home." --> Incorrect punctuation, should be "The last thing homework should do is cause friction in the home." (1 error)
- Sentence: "Homework should only take a small amount of time out of your day." --> Incorrect capitalization, should be "Homework should only take a small amount of time out of your day." (1 error)
- Sentence: "Students can still carry on enjoying there activities and enjoying their youth." --> "their" instead of "there" (1 error)
Count of spelling and grammar errors: 15
Language Score: 5 points
My count of how many times the GPT model believes there is an error is 18. So, you might say, anyone could fail to count them up correctly, which is a fair point. Looking back at the mark scheme, however, we have asked for more than 12 errors to receive a mark of 0-2 points. The essay was given 5 points. Further, there are a number of ‘errors’ that simply aren’t errors - and all errors are clearly not equal. Microsoft Word gives this essay 7 errors and two possibles.
If GPT were an examiner, they would immediately be stopped while the Chief got on the phone to ask what on earth they were thinking. The feedback on this essay was quite typical for all the essays I gave it. My favourite type of feedback is along the lines of: "sing with joy" should be "sing with joy". GPT continues to baffle.
Apparently the high kappa reported by the authors was achieved by fine-tuning the GPT model on 80% of the data-set of essays the authors used, and then marking the final 20% using the fine-tuned model. As the trained model hasn’t been made available to us it would be impossible to verify this claim, but what is clear is that even with the simplest possible rubric GPT fails to get close to a basic level of competence.
Chris Wheadon no longer believes he is using the wrong model or the wrong prompt. He just wishes this rabbit hole had never opened up in the first place.
This is a great post. There is so much noise in Ai at the moment but your experiences match mine - we are yet to see Ai mark work with any integrity. Thanks for sharing and brining a sensible voice to the discussion
Here is my experience with the ChatGPT. I have not used it to submit for grading but to generate text based on a prompt.
1. A sentence or two is/are always long-winded in every paragraph.
2. Excessive use of certain words: not only and transformative are two examples.
3. Some sentences repeat with slightly different wording if it is a 500+ word write-up.
4. Always requires updates to meet your needs and how you write, irrespective of how good your prompt is, because it largely feels emotionless. I expect we will all sound similar in the future if we all use the same models.
For now, I believe it can be used to give a starting point but cannot be used for a submission without significant updates.
The poem below by Shel Silverstein was written in 1981 and sums it up better than I would. I am not saying it is as bad as the machine in the poem is stating:
The Homework Machine
The Homework Machine,
Oh, the Homework Machine,
Most perfect
contraption that's ever been seen.
Just put in your homework, then drop in a dime,
Snap on the switch, and in ten seconds' time,
Your homework comes out, quick and clean as can be.
Here it is— 'nine plus four?' and the answer is 'three.'
Three?
Oh me . . .
I guess it's not as perfect
As I thought it would be.